
What is Retrieval-Augmented Generation (RAG) in AI?
One of the biggest challenges developers and users face in the world of artificial intelligence is dealing with “hallucinations” – moments when AI models produce confident-sounding but completely inaccurate information. While these moments are amusing in casual chats, this issue can pose a serious risk in professional or sensitive contexts.
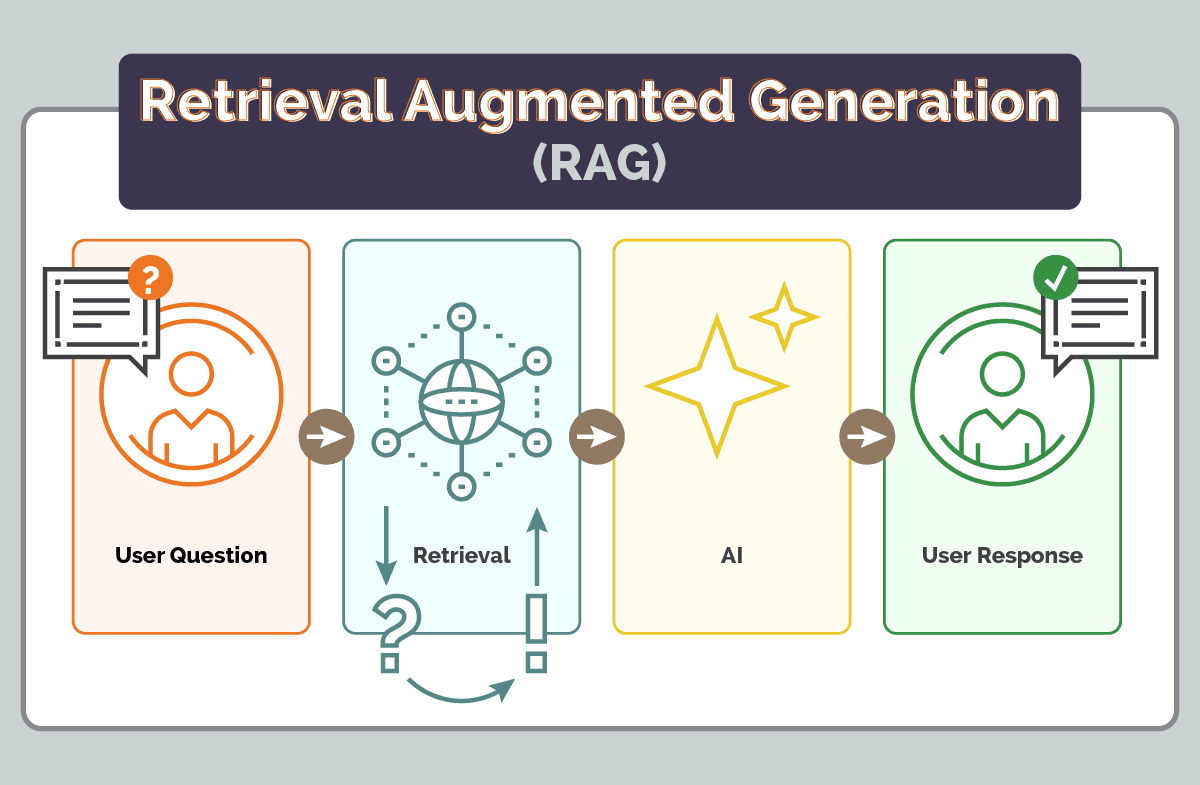
Retrieval-Augmented Generation (RAG) – a powerful architectural approach that aims to significantly reduce these hallucinations. RAG does this by allowing AI models to access external data sources at the time of generating a response. Instead of relying solely on the information encoded during the training period, RAG models retrieve real-time, relevant information, grounding their outputs in verifiable facts.
This dynamic makes RAG more reliable and much more adaptable to real-world use cases, particularly in industries like healthcare, law, and enterprise support, where accuracy matters most.
Overview of RAG Architecture
At its core, RAG is a hybrid system that marries two key components: a retriever and a generator. The retriever’s job is to scan a knowledge base and pull the most relevant documents or data snippets based on the user’s query. Then, the generator – typically a large language model (LLM) like GPT – synthesizes this information into a coherent, human-readable response.
What sets this apart from traditional AI models? The generator isn’t working in isolation. Instead of relying solely on its internal knowledge, which may be outdated or incomplete, it’s being fed fresh, relevant data on the fly. This architecture empowers AI to produce outputs that are not only plausible-sounding but grounded in reality.
How RAG Differs from Traditional AI Models
Traditional generative models operate like a closed book – they rely entirely on the data they’ve been trained on. While that training can be extensive, it’s also static. Once trained, the model’s knowledge is frozen in time. Updating it requires re-training or fine-tuning, which is often resource-intensive and slow.
But RAG changes the game by enabling AI to “look things up” in real time. Rather than guessing or extrapolating based on old, outdated knowledge, the model fetches current and contextually relevant data to guide its responses. This makes RAG far more scalable, especially for applications that require frequently updated or domain-specific information.
Comparison with Fine-Tuning and RLHF
While fine-tuning and Reinforcement Learning with Human Feedback (RLHF) have been essential in aligning language models with human preferences and values, they don’t solve the hallucination issue. Fine-tuning content outputs helps inject new knowledge, but the process is time-consuming. RLHF improves the quality of responses based on human feedback, but it doesn’t change the fact that the model’s information is still limited to what it was trained on.
RAG, by contrast, bypasses these limitations. It doesn’t need a training overhaul to access new data – it simply retrieves it from an external source. That makes RAG an elegant, cost-effective solution for maintaining up-to-date, trustworthy AI outputs.
How RAG Works
Key Components: Retriever and Generator
The brilliance of RAG lies in how the retriever and generator work together. The retriever is designed to search across a vast collection of documents – whether it’s internal knowledge bases, product manuals, or scientific research – to find the most semantically relevant pieces of information. It uses vector embeddings and semantic search to understand not just keywords, but the meaning behind queries.
Once those relevant chunks are identified, the generator takes over. This is typically a pre-trained LLM that knows how to take retrieved text and generate a response that is coherent, informative, and human-like. The result is a dynamic, real-time synthesis of stored knowledge and generative capability.
Integration of Structured and Unstructured Data
One of RAG’s strengths is its flexibility in dealing with both structured and unstructured data. While many AI systems struggle to make sense of unstructured formats – like PDF documents, blog posts, or conversation transcripts – RAG can understand these just as effectively as it does structured databases or spreadsheets.
This makes it especially helpful for enterprises where critical knowledge often lives in different formats. Whether it’s CRM logs, technical wikis, or customer support transcripts, RAG can pull relevant context from all of them – no data is left behind.
Utilization of Vector Databases and Semantic Search
The retriever component often relies on vector databases – such as Pinecone, FAISS, or Weaviate – to perform fast, accurate semantic search. These systems convert both the user query and the stored documents into high-dimensional vectors, allowing for sophisticated similarity matching based on meaning, not just words.
This method of retrieval is what allows RAG to outperform keyword-based systems. It understands context, nuance, and user intent, enabling it to pull up information that a simple search engine might miss entirely.
Reasons to Use RAG in Generative AI
Granting Response Accuracy
By grounding each answer in actual retrieved documents, RAG significantly reduces the guesswork that leads to hallucinations. It’s not just “thinking” based on its training – instead, it’s utilizing real data. This grounding ensures that the generated responses are more precise, verifiable, and aligned with the truth.
Providing Real-Time, Domain-Specific Information
One of the most compelling use cases for RAG is its ability to serve up real-time and domain-specific knowledge. Imagine an AI tool tailored to a hospital’s database of medical journals or a legal assistant trained to reference updated case law. RAG makes these use cases not only possible but practical.
Since you can update the retrieval layer independently of the model, there’s no need to retrain the entire system when new information becomes available. Just upload the new documents, and the AI will immediately have access to them.
Improving Contextual Relevance in AI Outputs
Context is king in AI, and RAG excels at delivering it. Because the retriever fetches relevant context for each new input, the generator can respond in a way that’s not only accurate but also tailored to the user’s query, making RAG valuable in customer support, content creation, and research assistance.

Understanding and Preventing AI Hallucinations
What Are AI Hallucinations?
AI hallucinations occur when a language model produces factually incorrect or entirely fabricated content. Sometimes, it’s subtle – a wrong date, a made-up quote. Other times, it’s more blatant – citing non-existent studies, misidentifying locations, or providing dangerous and potentially hurtful information. The confidence with which these hallucinations are delivered often makes them hard to spot, especially for non-expert users.
Why Generative Models Hallucinate
There are several underlying causes of hallucinations in traditional generative models:
- Lack of up-to-date information: Training data is frozen in time
- Gaps in knowledge: Even vast training sets can’t cover everything
- Pattern prediction bias: Models aim to predict plausible sequences, not necessarily truthful ones
- No retrieval mechanism: They can’t fact-check in real time.
Mitigation Strategies with RAG
RAG addresses hallucinations by grounding the generation process in reality. Instead of relying solely on prediction, RAG systems retrieve external documents that provide needed context. This means the model is building responses on top of actual evidence – not memory alone.
By enabling models to cite or reference actual sources, RAG can also offer transparency, helping users trace where information comes from.
Implementation of RAG in Real-World Applications
Personalizing User Interactions with RAG
RAG is already reshaping how businesses interact with customers. Imagine a RAG chatbot that doesn’t just provide basic, generic answers but responds based on your specific products, services, and past customer interactions. By feeding it custom documentation, company FAQs, or CRM data, businesses can deliver personalized results, accurate responses at scale.
This also cuts down on support tickets and increases customer satisfaction – all while ensuring that the answers align with company policy and tone.
Ensuring Response Accuracy in High-Stakes Use Cases
In high-stakes industries and YMYL sites like healthcare, legal services, or financial advising, a hallucinated answer can have dire consequences. RAG helps mitigate these risks by keeping the AI tethered to reliable, trustworthy data sources. The model isn’t just spouting what sounds right – it’s pulling from information that’s been vetted and approved.
Challenges in RAG Implementation
Data Source Reliability and Management
While RAG is powerful, it’s only as good as the data it retrieves. If the source material is outdated, incorrect, or poorly structured, the AI’s outputs will reflect those weaknesses. Implementing RAG effectively means investing in data hygiene, governance, and continual updates to your knowledge base.
Balancing Latency with Retrieval Quality
Adding a retrieval step naturally introduces some latency. The challenge is finding the right balance – you want retrieval to be fast enough for responsive interactions but also deep and accurate enough to surface the best content. Optimizing for speed while maintaining quality often requires fine-tuning your vector database settings and using smart caching strategies.

The Future of RAG and AI Accuracy
Trends in Multi-Agent and Multimodal Retrieval
Looking ahead, we’ll likely see RAG systems develop into multi-agent environments where different agents specialize in different types of retrieval. This paves the way for multimodal RAG, where the AI can pull in multiple content types to generate rich, layered responses.
Growing Adoption in Enterprise AI Products
From SaaS platforms to enterprise search tools, more companies are embedding RAG into their products. This trend is being driven by the need for explainability, trust, and data-specific insights. Expect to see more plug-and-play RAG solutions hitting the market, making it easier for digital marketing teams to adopt without building from scratch.
The Role of Open Source vs Proprietary RAG Models
Open-source frameworks like LangChain and Haystack have made it easier for developers to build and experiment with RAG architectures. At the same time, many enterprises are turning to proprietary solutions that offer enterprise-grade security, SLAs, and support. The choice often comes down to trade-offs between control, customization, and scale.